创作技巧:智能拆书
创作技巧:智能拆书
在 FeelFish 2.10.0 版本后,我们支持了智能拆书功能。你可以上传完整的一本小说的 txt 内容,会帮你拆分章节,并基于章节内容提取关键信息。帮你学习参考。
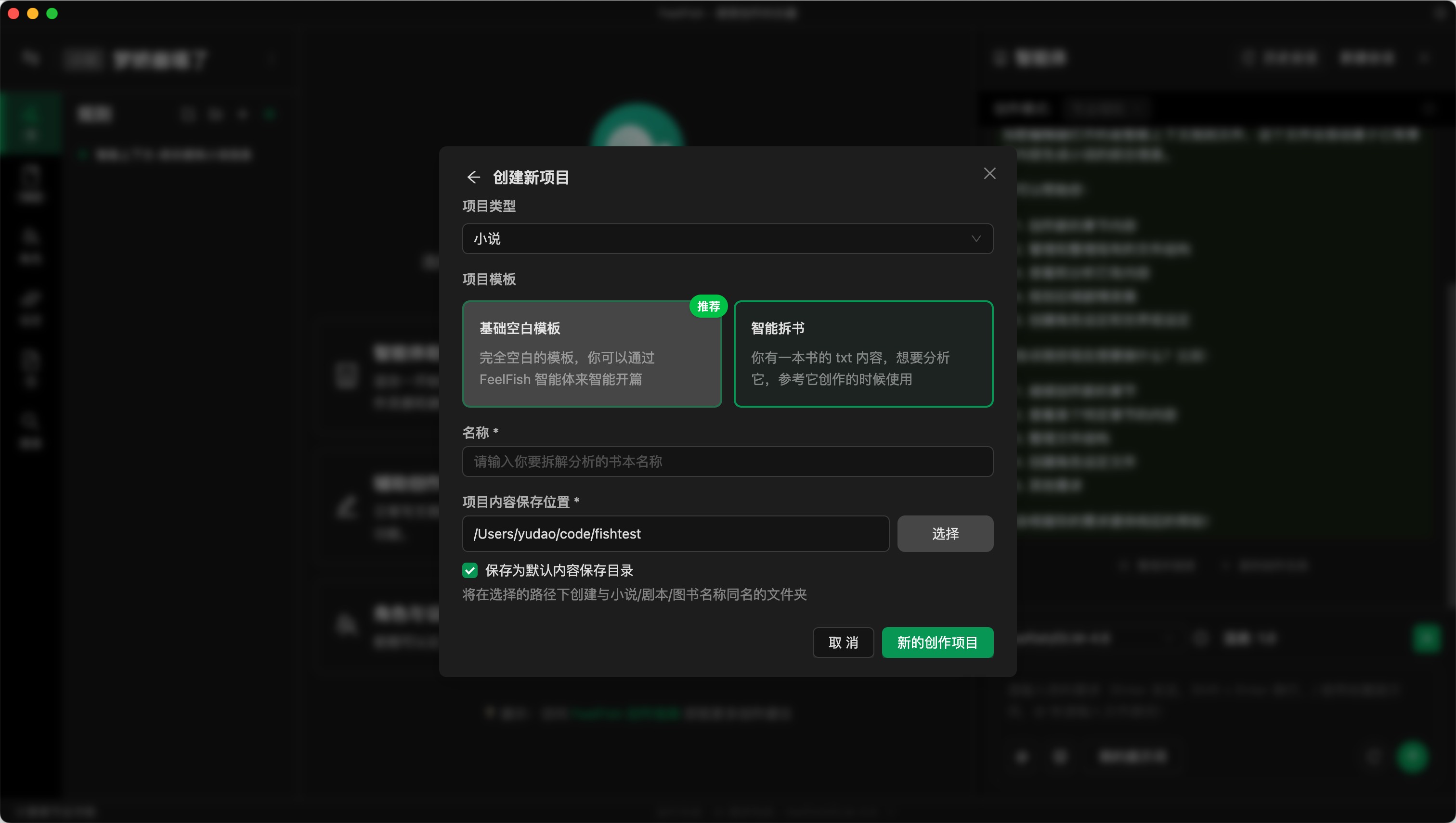
步骤一:基于智能拆书模板项目创建小说
点击小说名称左侧的切换项目按钮,然后点击“新的创作项目”,选择“智能拆书模板”,输入你要拆的书的名称,然后创建。
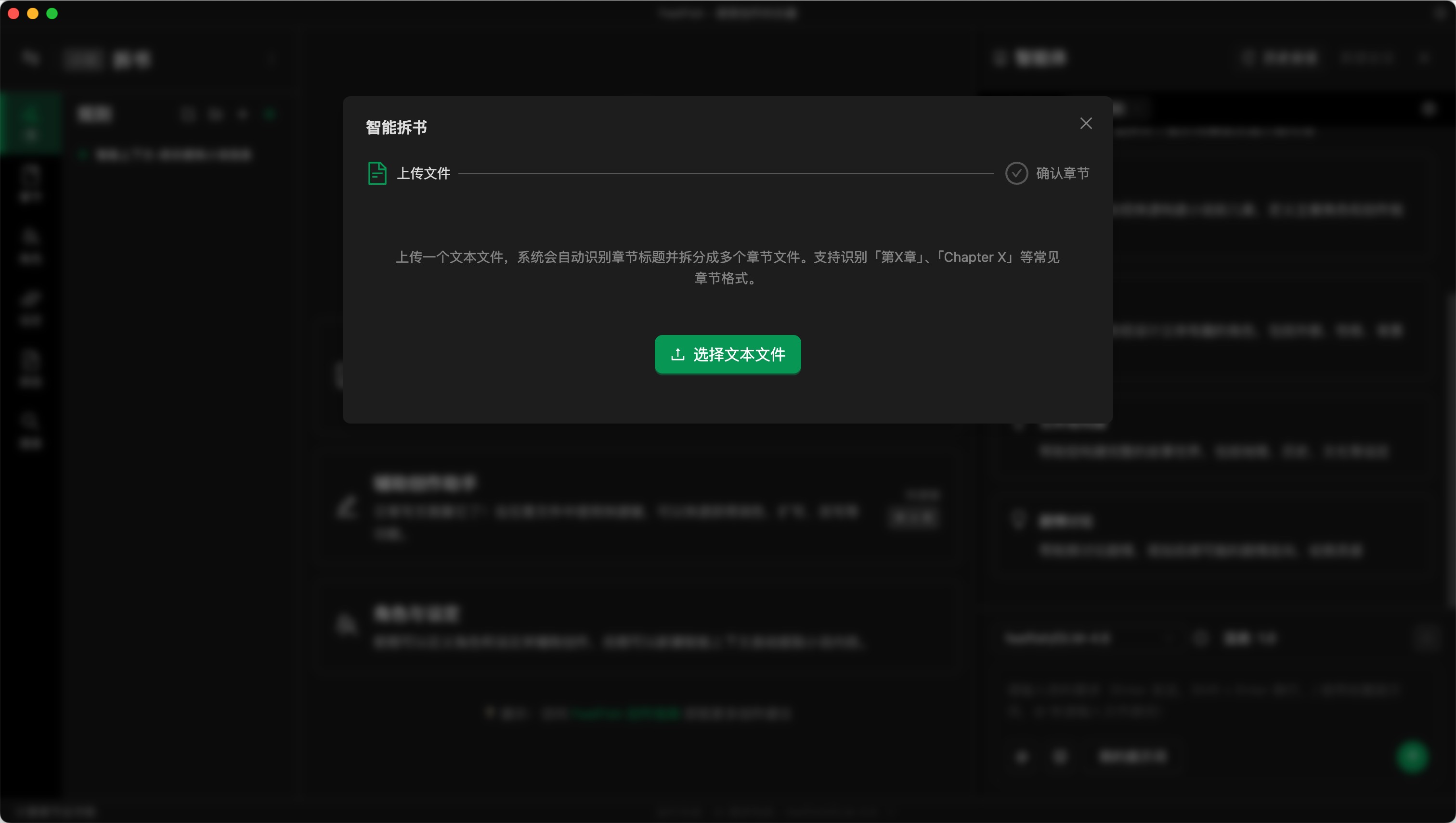
步骤二:导入完整的 TXT 文本
在弹出来的窗口中可以导入完整的 TXT 文本。或者当章节内容为空的时候,你也可以在章节内容列表那里找到导入按钮。
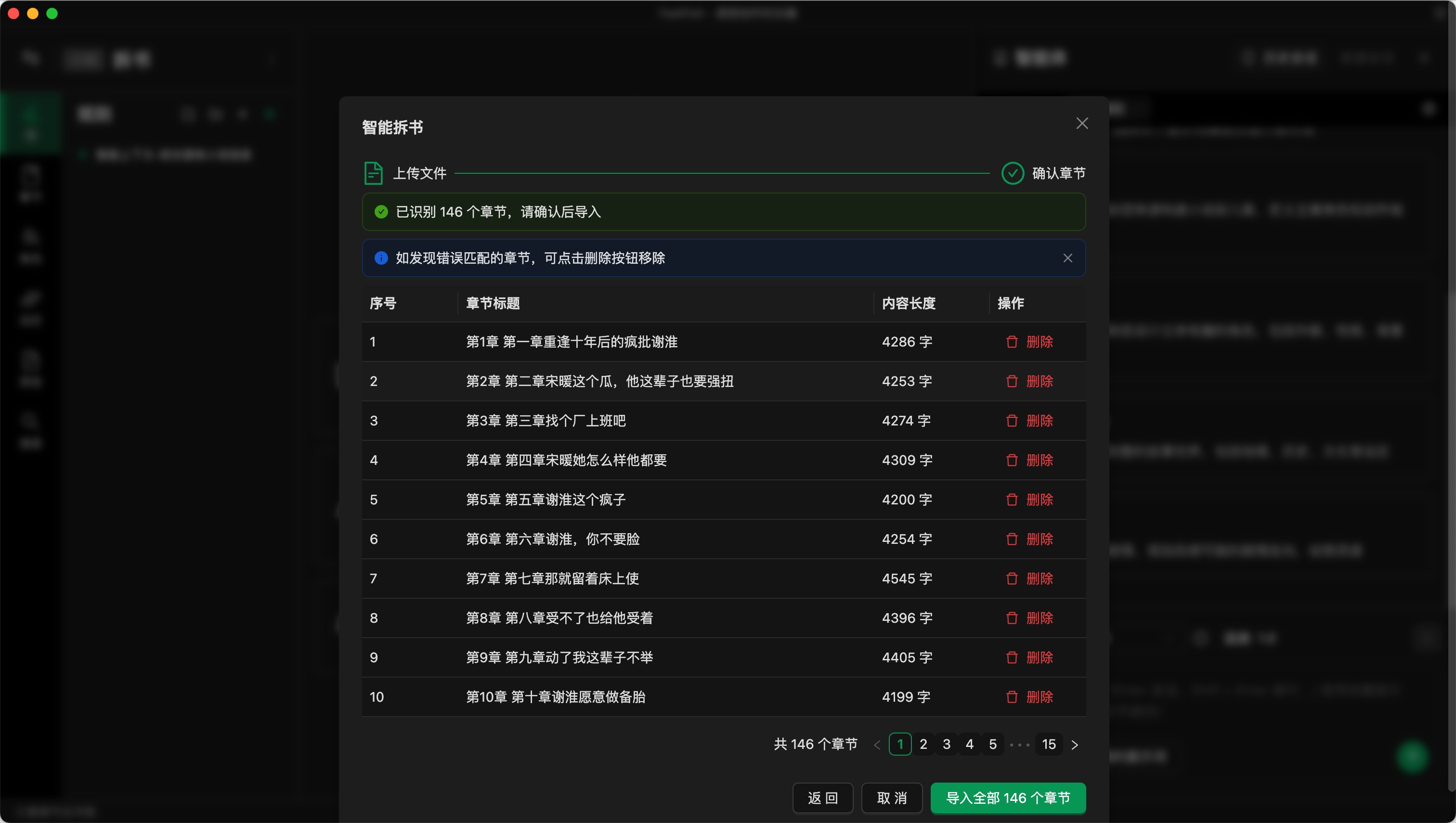
导入后会识别小说中的章节编号,把整个 TXT 拆解为独立的章节。这个过程可能会匹配出错,比如可能会把内容中单独一行出现的数字也匹配为章节号。你需要手动检查并删除错误的匹配。
如果匹配有问题,请反馈给我们。我们会看看是否是你的文本格式我们没有识别到。
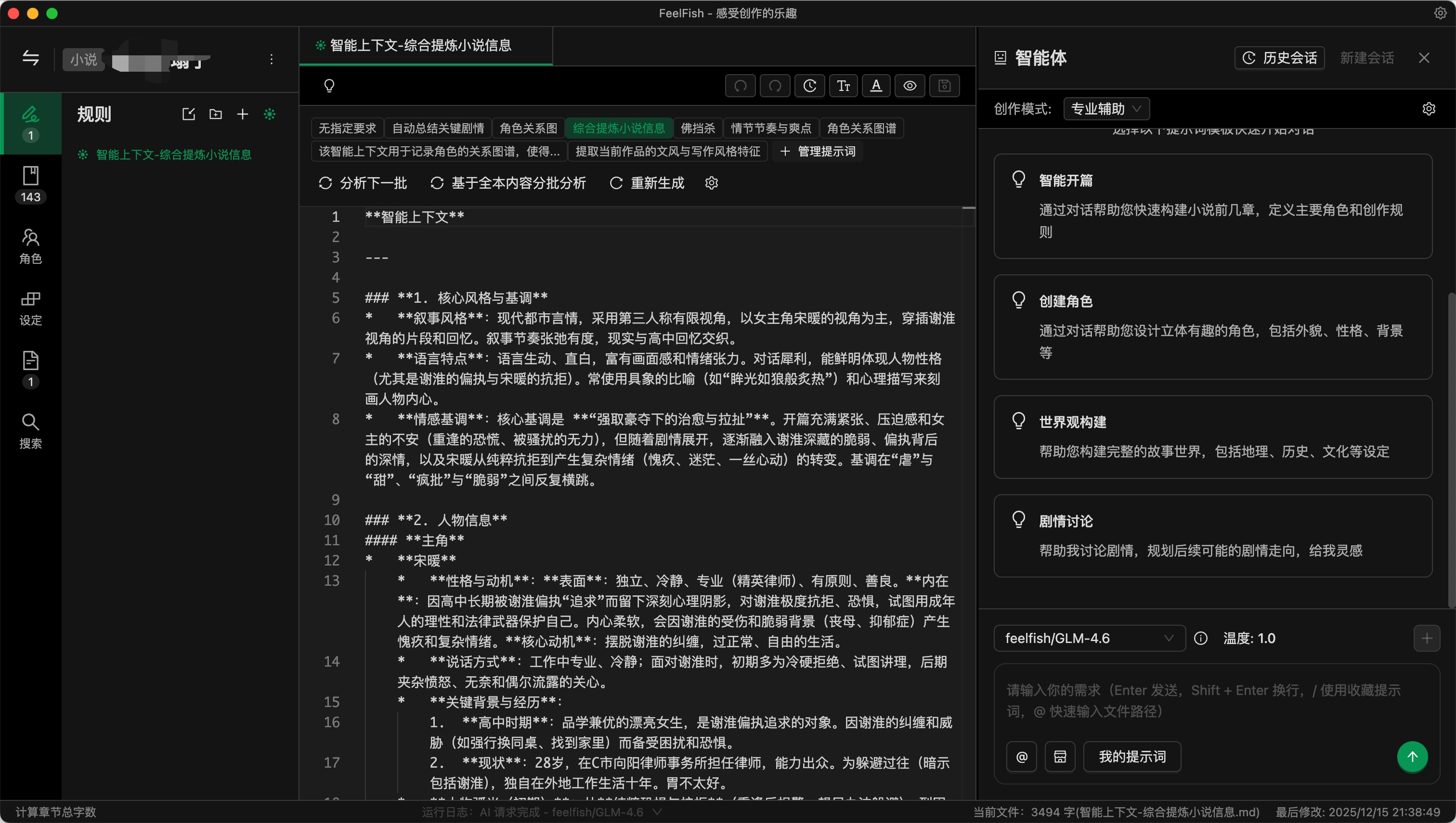
步骤三:基于智能上下文功能提取小说内容
智能拆书的原理其实就是基于 FeelFish 的智能上下文功能实现的。本质上就是基于小说章节分批识别,依靠 AI 提取小说内容。
智能上下文可以创建多个,你可以按照你的需求来提取不同的信息。每个智能上下文都可以有自己的提示词,FeelFish 会基于对应智能上下文的提示词来提取小说信息。
关于积分消耗
积分消耗和 FeelFish 的智能上下文功能一样,都是基于 AI 请求的 Token 数来计算的。你可以选择你要使用的模型来拆书,我们如果按照 DeepSeek V3.2 来算的话(每个输入的 token 消耗 28 积分),大概两个汉字对应一个 Token,一百万字对应 50W Token,只看小说内容输入的话需要 1400W 积分。加上最后的输出和每次分批时输入的上一次的智能上下文的结果,总消耗应该在 2000W 积分左右。
如果你新建多个智能上下文,一定时间内重复读取的小说内容是有缓存的,只需要十分之一的积分。所以整体来看,创建个三四个个智能上下文,积分消耗应该在 5000W 以内(相当于高级会员的六分之一,实际情况请以实际消耗为准)。我们建议可以先分析几个章节,看看效果如何。然后调整你的提示词后再全量跑。
另外,你可以可以在智能体中基于已有章节内容让 AI 帮你针对单个章节进行分析。
总之,FeelFish 的智能拆书功能非常的灵活和强大,你可以好好探索~