Guía de Precios de Modelos y Consumo de Créditos
Explicación del consumo de créditos 🔋
FeelFish consume créditos al realizar solicitudes a la IA para cubrir los costos de potencia de cálculo que cobran los proveedores de modelos de IA grandes. Diferentes modelos grandes consumen créditos a diferentes ritmos. El contenido enviado a la IA y el contenido devuelto por la IA también consumen cantidades diferentes de créditos.
Tomando como ejemplo el modelo DeepSeek V3.2 actualmente recomendado en FeelFish, aquí hay una explicación general de las reglas de consumo de créditos:
- ➡️ Usted envía inicialmente 100 caracteres a la IA, consumiendo aproximadamente 2000 créditos.
- ⬅️ La IA devuelve 100 caracteres, consumiendo aproximadamente 3000 créditos.
- 🔁 Usted continúa enviando otros 100 caracteres a la IA. Esta vez, incluye los 200 caracteres anteriores. Estos 200 caracteres también incurren en un costo, pero debido al almacenamiento en caché (caching), es mucho más económico: solo alrededor de una décima parte del costo original, aproximadamente 400 créditos. Sumando el costo de los nuevos 100 caracteres enviados, este paso consume 2400 créditos.
- 📈 Si continúa creando dentro de una sola conversación, los mensajes históricos enviados a la IA se acumularán. Sin embargo, hay un límite superior. Cuando se acerca a este límite, FeelFish activará automáticamente la compresión/resumen para reducir el consumo de créditos. Cuando esté cerca del límite superior, cada solicitud puede consumir aproximadamente 280,000 créditos (basado en el precio de la membresía anual, esto es aproximadamente ¥0.035 RMB).
Según nuestra experiencia, se estima que 100 millones de créditos pueden producir aproximadamente más de 100,000 caracteres 📚 si el proceso de creación es eficiente (con menos revisiones de ida y vuelta). Si hay más revisiones, podría producir alrededor de 20,000 a 30,000 caracteres ✍️. Por supuesto, teóricamente, 100 millones de créditos podrían devolver millones de caracteres. Sin embargo, en la creación real, los caracteres devueltos por la IA no equivalen directamente al contenido final de la novela. Por lo tanto, el consumo real depende de los hábitos de creación individuales. Por ejemplo, si prefiere usar el Panel de Creación Auxiliar en lugar del Agente, el consumo de créditos debería ser menor. Esto se debe a que cada nueva sesión del Panel de Creación Auxiliar es una nueva conversación y no lleva el costo de crédito de los mensajes históricos antiguos.
Preguntas frecuentes ❓
❓ ¿Por qué se consumen los créditos tan rápidamente?
Porque el contenido enviado a la IA también consume créditos. Cuando una conversación se vuelve demasiado larga, la cantidad de contenido enviado a la IA por solicitud aumenta significativamente, lo que lleva a un mayor consumo de créditos por solicitud. Sin embargo, debido al almacenamiento en caché, los mensajes históricos cuestan solo alrededor de una décima parte de los mensajes nuevos (para DeepSeek V3.2).
También es posible que esté utilizando un modelo como ChatGPT. Los modelos extranjeros generalmente tienen un consumo mayor. Por ejemplo, GPT-5.1 consume casi cinco veces los créditos de DeepSeek V3.2 ⚠️. Estos costos se pagan a los proveedores de modelos grandes por la potencia de cálculo. Por lo tanto, si tiene un presupuesto limitado, recomendamos elegir los modelos sugeridos para obtener la mejor relación calidad-precio 💰.
❓ ¿Hay formas de reducir el consumo de créditos?
- 🧠 Separación de tareas: Al crear con el Agente, inicie una nueva conversación para cada tarea independiente. De esta manera, cada tarea lleva menos historial contextual, lo que resulta en un consumo de créditos relativamente menor. Por ejemplo, después de escribir continuamente tres capítulos, si necesita agregar un nuevo personaje (una tarea no relacionada con la escritura de los capítulos anteriores), puede iniciar una nueva conversación para la tarea "agregar nuevo personaje".
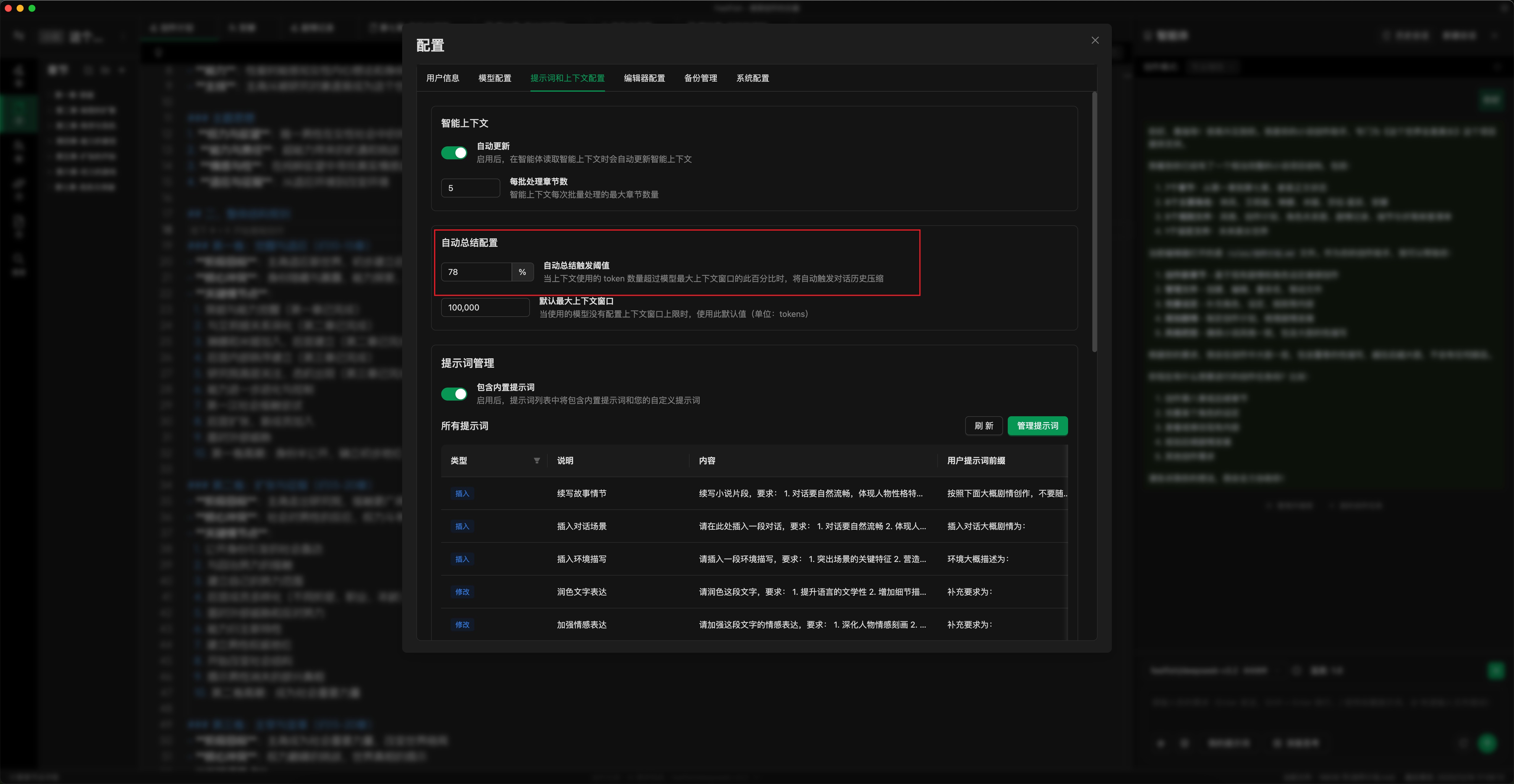
- ⚙️ Establecer umbral de auto-resumen: Como se muestra en la imagen a continuación, establezca el umbral de auto-resumen de acuerdo con su uso. Un umbral más bajo activa el resumen antes (también puede hacer clic manualmente en "Resumir y continuar"). Esto limita el consumo máximo de créditos por solicitud. El valor predeterminado es 78%; puede ajustarlo al 50-70%. (Ubicación de configuración: Ventana emergente de Configuración -> Indicaciones y Contexto -> Configuración de Auto-Resumen)
- ✏️ Usar el Panel de Creación Auxiliar: Para ediciones detalladas, use el Panel de Creación Auxiliar. Esto permite una modificación más precisa de contenido específico, reduciendo la cantidad de diálogos de ida y vuelta con la IA y disminuyendo el consumo de créditos.
- 💾 Usar servicios de modelos con almacenamiento en caché de entrada: Siempre que sea posible, use servicios de modelos con almacenamiento en caché de entrada (como DeepSeek). Esto reduce el costo de crédito de los mensajes históricos (por ejemplo, para DeepSeek V3.2, los mensajes históricos cuestan aproximadamente una décima parte de los mensajes nuevos).
- 🤖 Elegir el modelo correcto: Seleccione un modelo apropiado para sus tareas. Para la creación diaria, se recomienda usar el último modelo DeepSeek.
A medida que los modelos grandes continúan desarrollándose y la potencia de cálculo se vuelve más abundante, los precios cobrados por los proveedores de modelos grandes disminuirán. FeelFish ajustará correspondientemente sus reglas de consumo de créditos para esforzarse por brindar una mejor experiencia al usuario.
❓ ¿Cómo puedo ver el consumo de créditos para cada solicitud?
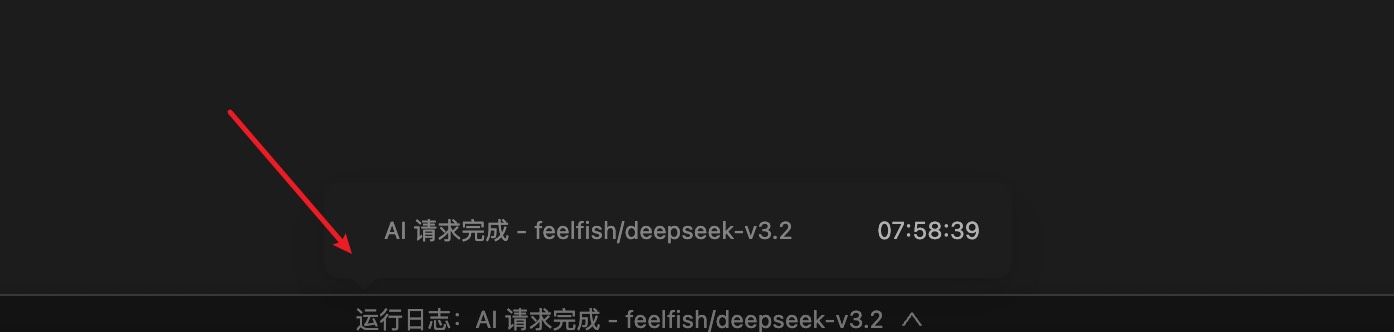
Puede ver el consumo de créditos para cada solicitud en el registro ubicado en la barra de estado en la parte inferior del editor del cliente FeelFish 📊.
❓ ¿Todos los modelos tienen almacenamiento en caché para mensajes históricos?
No, diferentes modelos tienen una lógica de almacenamiento en caché y precios diferentes. 🔍 DeepSeek almacena en caché mensajes históricos durante períodos que van desde decenas de minutos hasta varias horas. Sin embargo, su capacidad de almacenamiento en caché es generalmente confiable, con mensajes históricos que cuestan aproximadamente una décima parte de los mensajes nuevos. Para la mayoría de los usuarios, recomendamos usar el modelo predeterminado, que hemos seleccionado por su mejor rentabilidad.
Los modelos GPT-5.1 y GLM también tienen un almacenamiento en caché relativamente confiable pero son más caros 💸. La lógica de almacenamiento en caché para otros modelos es menos cierta, por lo que no se recomiendan para su uso dentro de Agentes (que se basan en diálogos de varios turnos que se benefician del caché para reducir el consumo). Sin embargo, se pueden usar en el Panel de Creación Auxiliar.
Explicación detallada del consumo de créditos 🔍
🔊 La mayor parte de los costos de FeelFish provienen del consumo de potencia de cálculo cobrado por los proveedores de modelos de IA grandes, correspondiente al consumo de Tokens de IA. FeelFish admite los principales modelos globales. Para la misma solicitud de IA, puede elegir diferentes modelos. Dado que diferentes modelos tienen diferentes precios de Tokens, FeelFish utiliza un sistema de crédito unificado para medir el consumo de potencia de cálculo.
Por lo tanto, diferentes modelos tienen sus propias tasas de consumo de crédito por Token. Tomando DeepSeek V3.2 como ejemplo: Cada millón de Tokens (correspondiendo aproximadamente a casi 2 millones de caracteres, teniendo en cuenta que los Tokens y los caracteres no son perfectamente equivalentes) para entrada consume 28,000,000 créditos, y para salida consume 42,000,000 créditos. Esto se traduce aproximadamente en 28 créditos consumidos por cada dos caracteres enviados, y 42 créditos por cada dos caracteres devueltos. ⚖️
🧑💻 Por supuesto, durante la creación real, la cantidad de Tokens consumidos para producir contenido es variable. Por lo tanto, el consumo real de créditos durante la creación depende del estilo de trabajo del creador.
Inicie sesión y visite Consumo de Créditos para ver el consumo real de créditos correspondiente a los Tokens para todos los modelos grandes admitidos. 🔗
Debido a las diferentes estrategias de almacenamiento en caché y precios de facturación entre modelos, este documento es solo para referencia. El costo final está sujeto a la facturación real del consumo de Tokens por parte de los proveedores de modelos grandes.