Modellpreise und Kreditverbrauch Leitfaden
Erklärung zum Credits-Verbrauch 🔋
Bei KI-Anfragen in FeelFish werden Credits verbraucht, um die Rechenleistungskosten der Anbieter großer KI-Modelle zu decken. Verschiedene KI-Modelle verbrauchen Credits unterschiedlich schnell. Sowohl die an die KI gesendeten Inhalte als auch die von der KI zurückgegebenen Inhalte verbrauchen unterschiedlich viele Credits.
Am Beispiel des aktuell von FeelFish empfohlenen DeepSeek V3.2-Modells finden Sie hier eine grobe Erläuterung der Verbrauchsregeln:
- ➡️ Sie senden erstmals 100 Zeichen an die KI und verbrauchen dabei etwa 2000 Credits.
- ⬅️ Die KI antwortet mit 100 Zeichen, was etwa 3000 Credits verbraucht.
- 🔁 Sie senden weitere 100 Zeichen an die KI. Dieses Mal werden die vorherigen 200 Zeichen mitgesendet. Auch diese 200 Zeichen verursachen Kosten, aber aufgrund von Caching ist es viel günstiger – nur etwa ein Zehntel der ursprünglichen Kosten, grob 400 Credits. Addiert man die Kosten für die neuen 100 Zeichen, werden in diesem Schritt 2400 Credits verbraucht.
- 📈 Wenn Sie das Schreiben in einem einzelnen Dialog fortsetzen, sammeln sich die historischen Nachrichten an, die an die KI gesendet werden. Es gibt jedoch eine Obergrenze. Wenn diese nahezu erreicht wird, löst FeelFish automatisch eine Komprimierung/Zusammenfassung aus, um den Credit-Verbrauch zu reduzieren. In der Nähe dieser Obergrenze kann eine Anfrage etwa 280.000 Credits verbrauchen (basierend auf dem Jahrestarif entspricht dies ungefähr 0,035 RMB Yuan).
Nach unserer Erfahrung können geschätzt 100 Millionen Credits bei effizienter Arbeitsweise (mit weniger Hin- und Her-Korrekturen) etwa über 100.000 Zeichen 📚 Text produzieren. Bei mehr Überarbeitungen könnten es etwa 20.000 bis 30.000 Zeichen ✍️ sein. Theoretisch könnten 100 Millionen Credits zwar Millionen von Zeichen zurückgeben, aber in der Praxis entsprechen die von der KI zurückgegebenen Zeichen nicht direkt dem endgültigen Roman-Text. Daher hängt der tatsächliche Verbrauch von den individuellen Arbeitsgewohnheiten ab. Wenn Sie beispielsweise lieber das Hilfsfenster fürs Schreiben (Auxiliary Creation Panel) nutzen als den Agenten, sollte der Credit-Verbrauch geringer sein, da jede neue Sitzung im Hilfsfenster ein neuer Dialog ist und nicht die Kosten alter historischer Nachrichten mit sich bringt.
Häufig gestellte Fragen ❓
❓ Warum werden Credits so schnell verbraucht?
Weil auch die an die KI gesendeten Inhalte Credits verbrauchen. Wenn ein Dialog zu lang wird, erhöht sich die Menge der pro Anfrage an die KI gesendeten Inhalte erheblich, was zu einem höheren Credit-Verbrauch pro Anfrage führt. Aufgrund von Caching kosten historische Nachrichten jedoch nur etwa ein Zehntel neuer Nachrichten (für DeepSeek V3.2).
Möglicherweise verwenden Sie auch ein Modell wie ChatGPT. Übersee-Modelle verbrauchen im Allgemeinen mehr Credits. Beispielsweise verbraucht GPT-5.1 fast das Fünffache an Credits von DeepSeek V3.2 ⚠️. Diese Kosten werden an die Anbieter großer KI-Modelle für Rechenleistung gezahlt. Wenn Sie ein begrenztes Budget haben, empfehlen wir daher, die vorgeschlagenen Modelle zu wählen, die das beste Preis-Leistungs-Verhältnis bieten 💰.
❓ Gibt es Möglichkeiten, den Credit-Verbrauch zu reduzieren?
- 🧠 Aufgaben trennen: Wenn Sie mit dem Agenten schreiben, starten Sie für jede unabhängige Aufgabe einen neuen Dialog. So hat jede Aufgabe weniger Kontext-Verlauf, was zu einem relativ geringeren Credit-Verbrauch führt. Wenn Sie beispielsweise drei Kapitel geschrieben haben und nun einen neuen Charakter hinzufügen möchten – eine Aufgabe, die nichts mit dem Schreiben der vorherigen Kapitel zu tun hat – können Sie für die Aufgabe "Neuen Charakter hinzufügen" einen neuen Dialog starten.
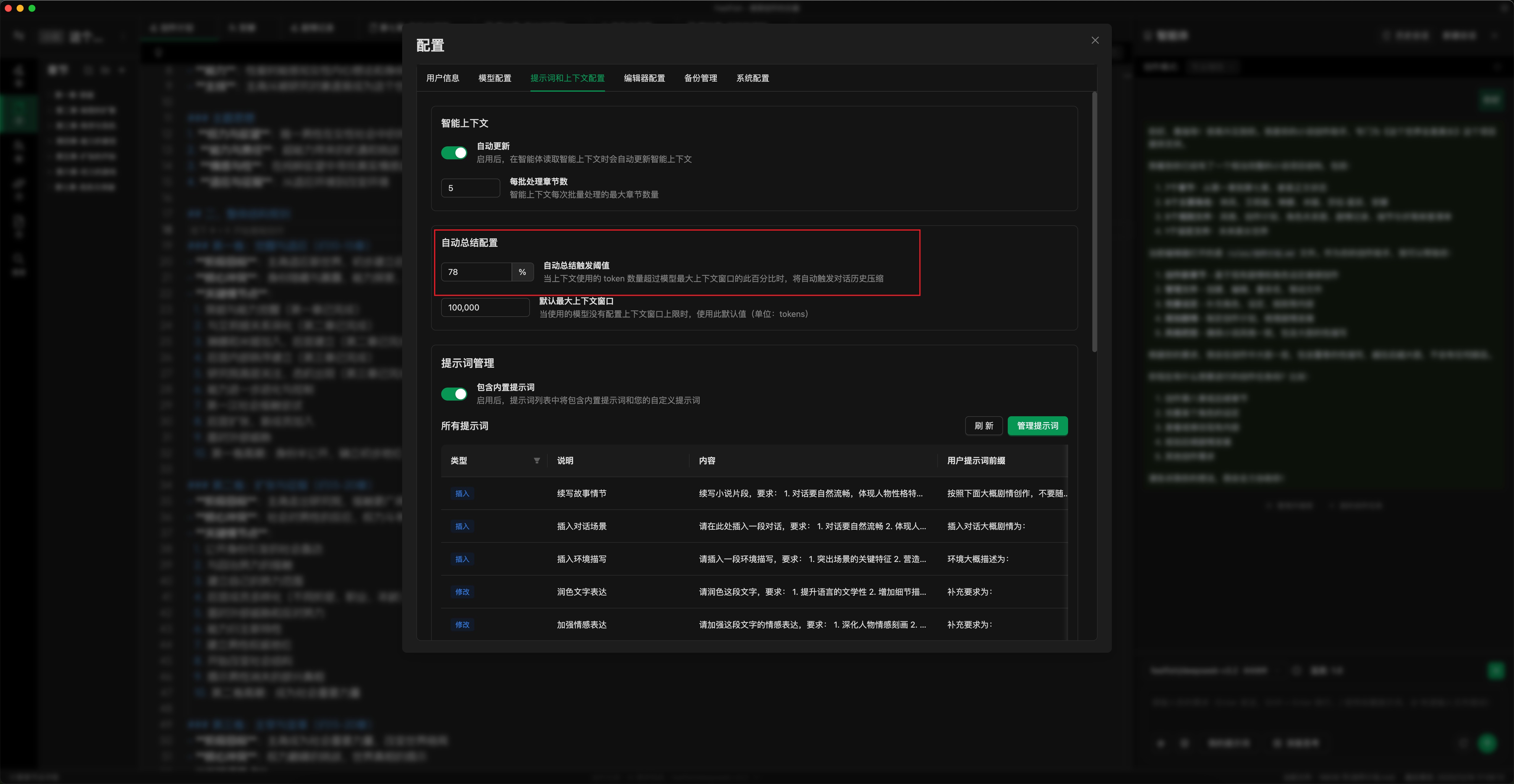
- ⚙️ Automatische Zusammenfassungs-Schwelle einstellen: Wie im Bild unten gezeigt, stellen Sie die Schwelle für die automatische Zusammenfassung entsprechend Ihrer Nutzung ein. Ein niedrigerer Schwellenwert löst die Zusammenfassung früher aus (Sie können auch manuell auf "Zusammenfassen und fortsetzen" klicken). Dies begrenzt den maximalen Credit-Verbrauch pro Anfrage. Der Standardwert ist 78 %; Sie können ihn auf 50–70 % einstellen. (Konfigurationsort: Einstellungs-Popup -> Prompts & Kontext -> Einstellungen für automatische Zusammenfassung)
- ✏️ Hilfsfenster fürs Schreiben nutzen: Für detaillierte Bearbeitungen nutzen Sie das Hilfsfenster fürs Schreiben. Dies ermöglicht eine präzisere Bearbeitung bestimmter Inhalte, reduziert die Anzahl der Hin- und Her-Dialoge mit der KI und senkt so den Credit-Verbrauch.
- 💾 Modelldienste mit Input-Caching nutzen: Verwenden Sie nach Möglichkeit Modelldienste mit Input-Caching (wie DeepSeek). Dies reduziert die Credit-Kosten für historische Nachrichten (z. B. kosten historische Nachrichten bei DeepSeek V3.2 etwa ein Zehntel neuer Nachrichten).
- 🤖 Passendes Modell wählen: Wählen Sie ein geeignetes Modell für Ihre Aufgaben. Für das tägliche Schreiben wird die Verwendung des neuesten DeepSeek-Modells empfohlen.
Da sich große KI-Modelle ständig weiterentwickeln und Rechenleistung reichlicher verfügbar wird, werden die Preise der Anbieter großer Modelle sinken. FeelFish wird die Credit-Verbrauchsregeln entsprechend anpassen, um bestmögliche Nutzererfahrungen zu bieten.
❓ Wie kann ich den Credit-Verbrauch für jede Anfrage einsehen?
Sie können den Credit-Verbrauch für jede Anfrage im Protokoll der Statusleiste am unteren Rand des FeelFish-Client-Editors einsehen 📊.
❓ Haben alle Modelle Caching für historische Nachrichten?
Nein, verschiedene Modelle haben unterschiedliche Caching-Logik und Preisgestaltung. 🔍 DeepSeek cached historische Nachrichten für Zeiträume von mehreren zehn Minuten bis zu mehreren Stunden. Seine Caching-Fähigkeit ist jedoch allgemein zuverlässig, wobei historische Nachrichten etwa ein Zehntel neuer Nachrichten kosten. Für die meisten Nutzer empfehlen wir das Standardmodell, das wir aufgrund seiner besseren Kostenwirksamkeit ausgewählt haben.
GPT-5.1- und GLM-Modelle haben ebenfalls relativ zuverlässiges Caching, sind aber teurer 💸. Die Caching-Logik anderer Modelle ist weniger sicher, daher werden sie nicht für die Verwendung in Agenten empfohlen (die auf Mehrfachdialogen basieren, die vom Cache profitieren). Sie können jedoch im Hilfsfenster fürs Schreiben verwendet werden.
Detaillierte Erklärung zum Credit-Verbrauch 🔍
🔊 Der Großteil der Kosten von FeelFish entsteht durch den Verbrauch von Rechenleistung, den Anbieter großer KI-Modelle in Rechnung stellen, entsprechend dem KI-Token-Verbrauch. FeelFish unterstützt große globale Modelle. Für dieselbe KI-Anfrage können Sie verschiedene Modelle wählen. Da verschiedene Modelle unterschiedliche Token-Preise haben, verwendet FeelFish ein einheitliches Credit-System, um den Rechenleistungsverbrauch zu messen.
Daher haben verschiedene Modelle ihre eigenen Credit-Verbrauchssätze pro Token. Am Beispiel von DeepSeek V3.2: Jede Million Token (entspricht grob fast 2 Millionen Zeichen – Tokens und Zeichen sind nicht völlig äquivalent) für die Eingabe verbraucht 28.000.000 Credits, für die Ausgabe 42.000.000 Credits. Das entspricht in etwa 28 verbrauchten Credits für alle zwei gesendeten Zeichen und 42 Credits für alle zwei zurückgegebenen Zeichen. ⚖️
🧑💻 Natürlich ist bei der tatsächlichen Texterstellung die Anzahl der verbrauchten Tokens variabel. Daher hängt der tatsächliche Credit-Verbrauch während des Schreibens vom Arbeitsstil des Autors ab.
Bitte melden Sie sich an und besuchen Sie Credit-Verbrauch, um den tatsächlichen Credit-Verbrauch entsprechend der Tokens für alle unterstützten großen Modelle einzusehen. 🔗
Aufgrund unterschiedlicher Caching-Strategien und Abrechnungspreise der Modelle dient dieses Dokument nur als Referenz. Die endgültigen Kosten richten sich nach der tatsächlichen Token-Verbrauchsabrechnung der Anbieter großer KI-Modelle.