モデル価格とクレジット消費ガイド
クレジット消費の説明 🔋
FeelFishがAIリクエストを行う際、大規模AIモデルプロバイダーへの計算リソースコストを賄うためにクレジットを消費します。異なるAIモデルはクレジットを異なる速度で消費します。AIに送信するコンテンツとAIから返されるコンテンツも異なる量のクレジットを消費します。
現在FeelFishで推奨されているDeepSeek V3.2モデルを例に、クレジット消費ルールの概要を説明します:
- ➡️ 最初に100文字をAIに送信すると、約2000クレジットを消費します。
- ⬅️ AIが100文字を返信すると、約3000クレジットを消費します。
- 🔁 さらに100文字をAIに送信する場合、前回までの200文字も含まれます。この200文字もコストがかかりますが、キャッシュにより大幅に安くなります。約1/10のコスト、つまり約400クレジットです。新たに送信する100文字のコストと合わせ、このステップでは2400クレジットを消費します。
- 📈 1つの会話内で作成を続ける場合、AIに送信される過去のメッセージが蓄積されます。ただし上限があり、上限に近づくと、FeelFishは自動的に圧縮/要約を実行してクレジット消費を削減します。上限付近では、1リクエストあたり約280,000クレジットを消費することがあります(年間メンバーシップ価格に基づくと、約0.035元相当です)。
経験上、効率的な作成プロセス(往復修正が少ない場合)では、1億クレジットで約10万字以上 📚 のテキストを作成できます。修正が多い場合は、約2万〜3万字 ✍️ 程度になる可能性があります。理論上、1億クレジットで数百万文字を返すことは可能ですが、実際の作成ではAIから返される文字が最終的な小説コンテンツに直接対応するわけではありません。したがって、実際の消費は個人の作業習慣に依存します。例えば、エージェントではなく補助作成パネル(Auxiliary Creation Panel) を好んで使用する場合、クレジット消費は少なくなるはずです。なぜなら、補助作成パネルの新しいセッションはそれぞれ新しい会話であり、古い過去メッセージのコストを引き継がないためです。
よくある質問 ❓
❓ クレジットがなぜこんなに速く消費されるのですか?
AIに送信するコンテンツもクレジットを消費するためです。会話が長くなると、1リクエストあたりAIに送信されるコンテンツ量が大幅に増加し、1リクエストあたりのクレジット消費が高くなります。ただし、キャッシュにより、過去のメッセージは新しいメッセージの約1/10のコストです(DeepSeek V3.2の場合)。
ChatGPTなどのモデルを使用している可能性もあります。海外モデルは一般的により多くの消費があります。例えば、GPT-5.1はDeepSeek V3.2のほぼ5倍のクレジットを消費します ⚠️。これらのコストは計算リソースに対する大規模AIモデルプロバイダーへの支払いです。予算が限られている場合は、推奨モデルを選択することをお勧めします。これらが最もコストパフォーマンスに優れています 💰。
❓ クレジット消費を減らす方法はありますか?
- 🧠 タスクの分離:エージェントで作成する際、独立したタスクごとに新しい会話を開始します。これにより、各タスクはより少ないコンテキスト履歴を引き継ぎ、相対的にクレジット消費が少なくなります。例えば、3章を連続して執筆した後、新しいキャラクターを追加する必要がある場合(前の3章の執筆とは関係のないタスク)、「新しいキャラクターを追加」タスクのために新しい会話を開始できます。
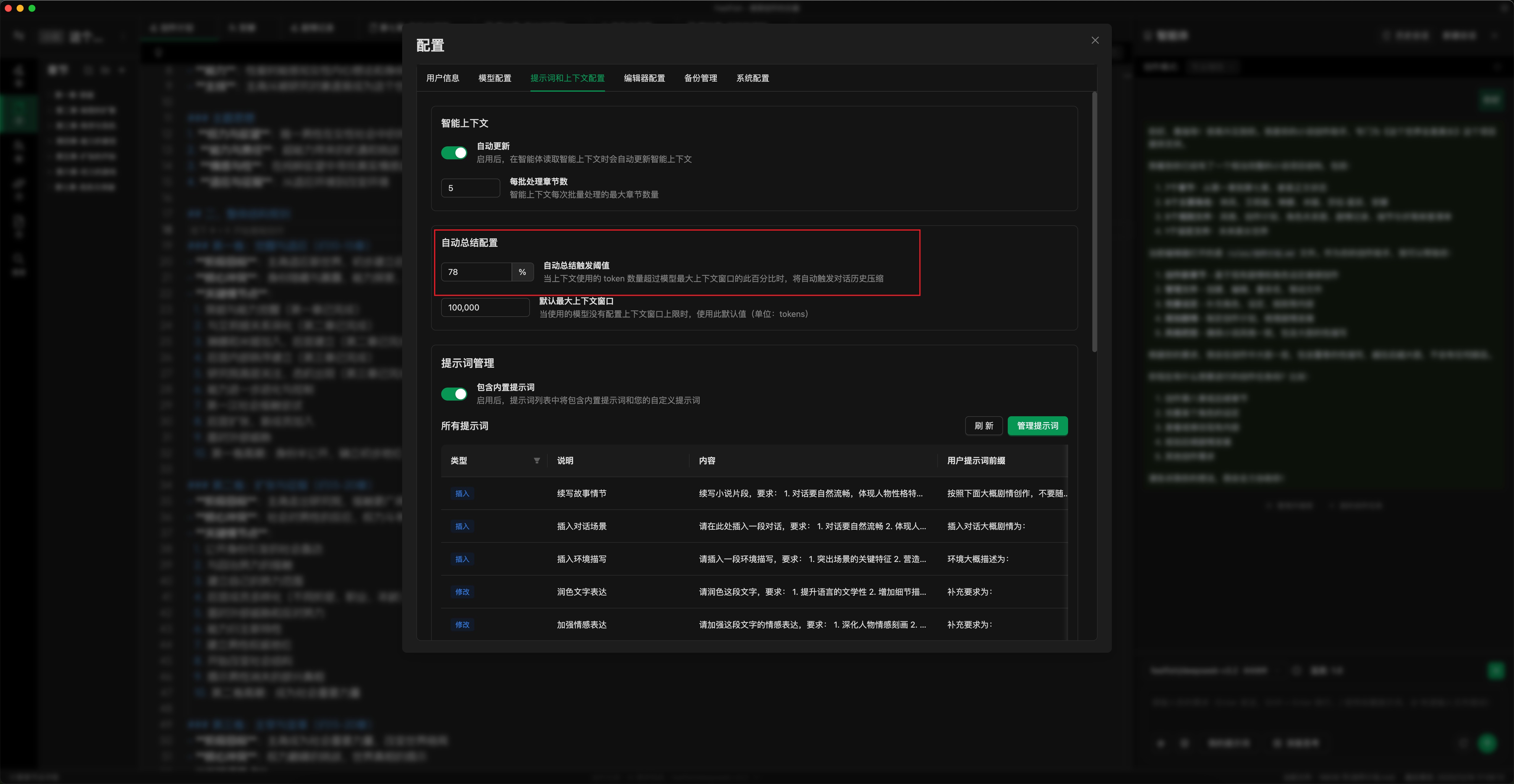
- ⚙️ 自動要約閾値の設定:下図のように、使用状況に応じて自動要約の閾値を設定します。閾値を低くすると、要約が早く実行されます(「要約して続行」を手動でクリックすることもできます)。これにより、1リクエストあたりの最大クレジット消費が制限されます。デフォルトは78%です。50〜70%に調整できます。(設定場所:設定ポップアップ -> プロンプトとコンテキスト -> 自動要約設定)
- ✏️ 補助作成パネルの使用:詳細な編集には補助作成パネルを使用します。これにより、特定のコンテンツをより正確に修正でき、AIとの往復対話回数を減らし、クレジット消費を削減できます。
- 💾 入力キャッシュ付きモデルサービスの使用:可能な限り入力キャッシュ付きのモデルサービス(DeepSeekなど)を使用します。これにより、過去メッセージのクレジットコストが削減されます(例:DeepSeek V3.2の場合、過去メッセージは新しいメッセージの約1/10のコストです)。
- 🤖 適切なモデルの選択:タスクに適したモデルを選択します。日常の作成には、最新のDeepSeekモデルの使用をお勧めします。
大規模AIモデルの継続的な発展と計算リソースの充実に伴い、大規模モデルプロバイダーの価格は低下していきます。FeelFishはクレジット消費ルールを適宜調整し、より良いユーザー体験を提供するよう努めます。
❓ 各リクエストのクレジット消費を確認するにはどうすればよいですか?
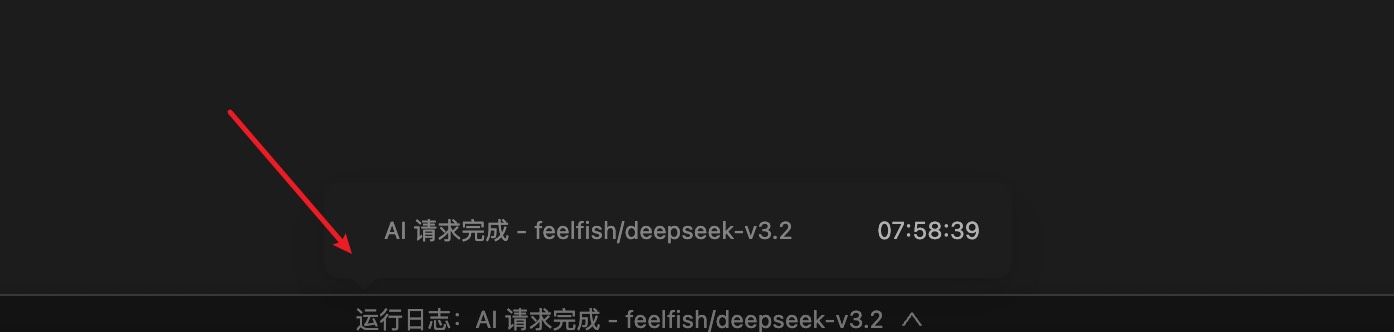
FeelFishクライアントエディター下部のステータスバーにあるログで、各リクエストのクレジット消費を確認できます 📊。
❓ すべてのモデルに過去メッセージのキャッシュ機能はありますか?
いいえ、モデルによってキャッシュの仕組みと価格が異なります。 🔍 DeepSeekは過去メッセージを数十分から数時間の期間キャッシュします。そのキャッシュ能力は一般的に信頼性が高く、過去メッセージは新しいメッセージの約1/10のコストです。ほとんどのユーザーには、コストパフォーマンスが優れているため、デフォルトモデルの使用をお勧めします。
GPT-5.1およびGLMモデルも比較的信頼性の高いキャッシュ機能がありますが、より高価です 💸。他のモデルのキャッシュ仕組みは不明確なため、エージェント内での使用はお勧めしません(複数ターンの対話は消費削減のためにキャッシュに依存します)。ただし、補助作成パネルでは使用できます。
クレジット消費の詳細説明 🔍
🔊 FeelFishのコストの大部分は、大規模AIモデルプロバイダーが請求する計算リソースの消費、つまり対応するAIトークンの消費に由来します。FeelFishは主要なグローバルモデルをサポートしています。同じAIリクエストに対して、異なるモデルを選択できます。モデルによってトークン価格が異なるため、FeelFishは計算リソース消費を測定するために統一されたクレジットシステムを使用しています。
したがって、異なるモデルにはトークンあたりの独自のクレジット消費率があります。 DeepSeek V3.2を例にすると: 入力100万トークン(ほぼ200万字に相当、トークンと文字は完全に同等ではありません)あたり28,000,000クレジットを消費し、出力には42,000,000クレジットを消費します。 これは、送信される2文字ごとに約28クレジット、返される2文字ごとに約42クレジットが消費されることを大まかに意味します。 ⚖️
🧑💻 もちろん、実際の文章作成では、コンテンツを生成するために消費されるトークン数は変動します。したがって、作成中の実際のクレジット消費は、作成者の作業スタイルに依存します。
サポートされているすべての大規模モデルについて、トークンに対応する実際のクレジット消費を確認するには、ログインして クレジット消費 ページにアクセスしてください。 🔗
モデル間でキャッシュ戦略と課金価格が異なるため、このドキュメントは参考情報です。最終的なコストは、大規模AIモデルプロバイダーによる実際のトークン消費の課金に準じます。