模型价格和积分消耗说明
积分消耗说明 🔋
FeelFish 请求 AI 时会消耗积分,用于支付大模型厂商的算力成本,不同的大模型消耗积分的快慢不同。发送给 AI 的内容和 AI 返回的内容消耗的积分也不同。
以目前 FeelFish 推荐的 DeepSeek V3.2 为例,下面是大概的积分消耗规则说明:
- ➡️ 你首次发送给 AI 100 个字,消耗大约 2000 个积分。
- ⬅️ AI 返回 100 个字,消耗大约 3000 个积分。
- 🔁 你再继续发送给 AI 100 个字,这次会带上前面的 200 个字,这两百个字也会消耗,但是因为有缓存所以会更便宜,只需要十分之一的积分,大概 400 积分。加上这次新发送给 AI 的 100 个字,会消耗 2400 积分。
- 📈 如果持续在一个对话中创作,发送给 AI 的历史消息也会越来越多,不过最终会到达上限,接近上限的时候 FeelFish 会触发自动整理压缩,降低积分消耗,接近上限时每次请求会消耗大概 280,000 个积分(按照年度会员的价格,大约消耗 3.5 分钱人民币)。
按照我们的经验估算,一亿个积分如果创作得比较高效(来回修改比较少)大概可以创作 十多万字 📚。如果改动比较多,大概可以创作 两三万字 ✍️。当然,理论上来说,一亿积分是可以返回上百万字的,但是实际创作的时候 AI 返回的字并不等于最终小说的内容,所以具体的消耗还要看个人创作的习惯,比如如果你习惯基于辅助创作面板创作,而不是用智能体,那么积分消耗应该会更少,因为每次新开辅助创作面板,都是新的对话,不会包含老的历史消息的积分消耗。
常见问题 ❓
❓ 为什么积分消耗这么快?
因为发送给 AI 的内容也会消耗积分,对话太长之后每次发送给 AI 的内容会太多。每次请求的积分消耗也会越来越多,不过历史消息因为有缓存,积分消耗只有新消息的十分之一(针对 DeepSeek V3.2 来说)。
也有可能是你用了 ChatGPT 这样的模型,海外模型一般消耗都更大,比如 gpt-5.1 是 deepseek-3.2 的近五倍消耗 ⚠️。这些消耗都是付给大模型厂商的算力成本,所以如果你预算有限,建议选择推荐的模型,性价比最高 💰。
❓ 有什么方法可以减少积分的消耗?
- 🧠 任务分离:在智能体中创作的时候,每个独立的任务新开对话,这样每个任务历史消息携带上下文比较少,消耗的积分也相对较少。比如你连续创作了三章之后,接下来要新增一个新的角色,新增角色这个任务和前面创作三章的任务没有关系,那么你可以新开对话来创作新增角色这个任务。
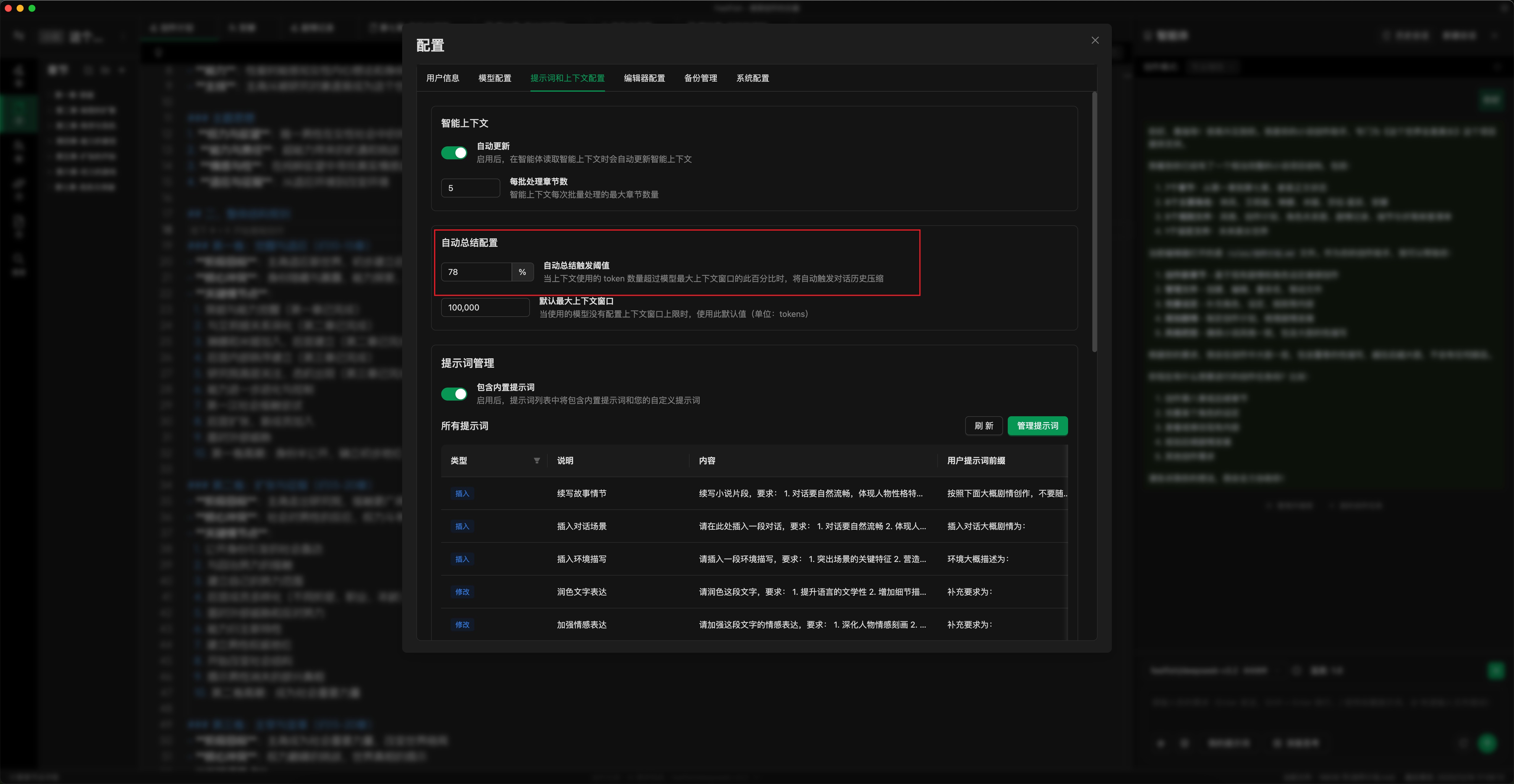
- ⚙️ 设置自动整理阈值:如下图,结合自己使用情况设置自动整理的阈值,阈值越低,会更早出发自动整理(当然你也可以选择手动点击“整理并继续”手动触发),请求所消耗的积分上限越小。默认是 78%,你可以调低到 50~70%。(配置位置:设置弹窗->提示词和上下文->自动总结配置)
- ✏️ 使用辅助创作面板:精细化的修改可以使用辅助创作面板,更加精准的修改指定内容,减少和 AI 来回对话的次数,降低积分消耗。
- 💾 使用带输入缓存的模型服务:尽量使用带输入缓存的模型服务(比如 DeepSeek),这样历史消息的积分消耗会更少(比如对于 DeepSeek V3.2 来说,历史消息所带来的积分消耗是新消息的十分之一)
- 🤖 选择合适的模型:选择合适的模型创作,日常创作推荐使用 DeepSeek 最新模型。
伴随大模型持续发展和算力的丰富,大模型厂商的模型价格也会越来越低,FeelFish 也会对应调整积分消耗规则,争取给大家带来更好的体验。
❓ 如何查看每次请求的积分消耗
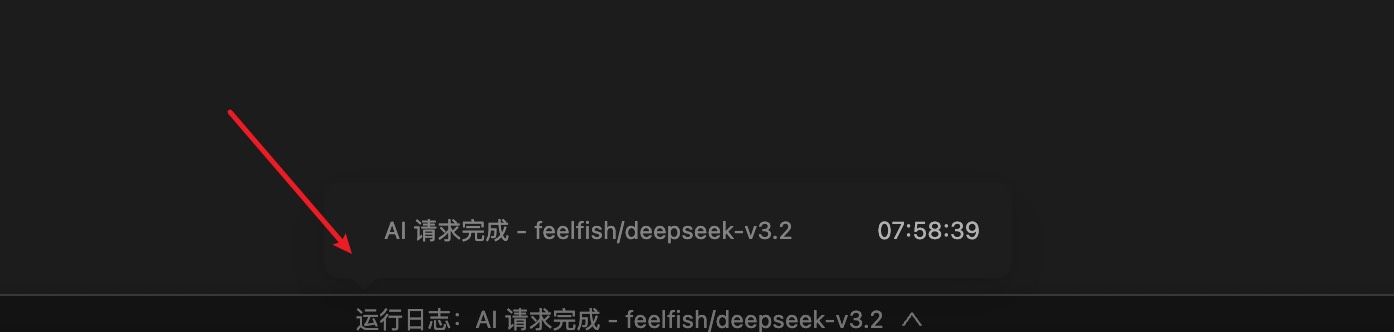
你可以在 FeelFish 客户端编辑器下面状态栏的日志中查看每次请求的积分消耗 📊。
❓ 所有模型都有历史消息缓存吗?
不是,不同模型的缓存逻辑和价格都不一样。🔍 DeepSeek 针对历史消息会有几十分钟到几个小时时间不等的缓存,不过基本上缓存能力是确定的,历史消息所带来的积分消耗是新消息的十分之一。对于大部分用户来说,推荐使用默认的模型,这是我们挑选出来的更具有性价比的模型。
GLM 模型的缓存也相对确定,但是价格更贵一点 💸。其它模型的缓存逻辑不确定,不建议在智能体中使用(多轮对话会依赖缓存减少积分消耗),但是可以在辅助创作面板中使用。
积分消耗详细说明 🔍
🔊 FeelFish 的大部分成本都来自于大模型厂商的算力消耗,也就是对应 AI 的 Token 消耗。FeelFish 支持全球主流模型,同一个 AI 请求可以选择不同的模型,因为不同的模型 Token 价格不同,所以 FeelFish 通过统一的积分来衡量算力的消耗。
所以不同的模型的 Token 有各自的积分消耗的价格,以 DeepSeek V3.2 为例,每百万个 Token(大概对应近两百万字,Token 和字数并不是完全对应的)输入需要消耗 28,000,000 个积分,输出需要消耗 42,000,000 个积分。差不多就是发送两个字需要消耗 28 个积分,返回两个字需要消耗 42 个积分。 ⚖️
🧑💻 当然实际创作的时候,创作出一个消耗的 Token 是不确定的,所以真正创作的时候积分的消耗取决于创作者的创作方式。
所有大模型实际 Token 对应的积分消耗请登录后访问 积分消耗 查看。 🔗
因为不同的模型缓存策略和计费价格不同,本文档仅供参考,最终以大模型厂商的实际 Token 消耗计费为准。