創作技巧:智能拆書
創作技巧:智能拆書
在 FeelFish 2.10.0 版本後,我們支援了智能拆書功能。你可以上傳完整的一本小說的 txt 內容,會幫你拆分章節,並基於章節內容提取關鍵信息。幫你學習參考。
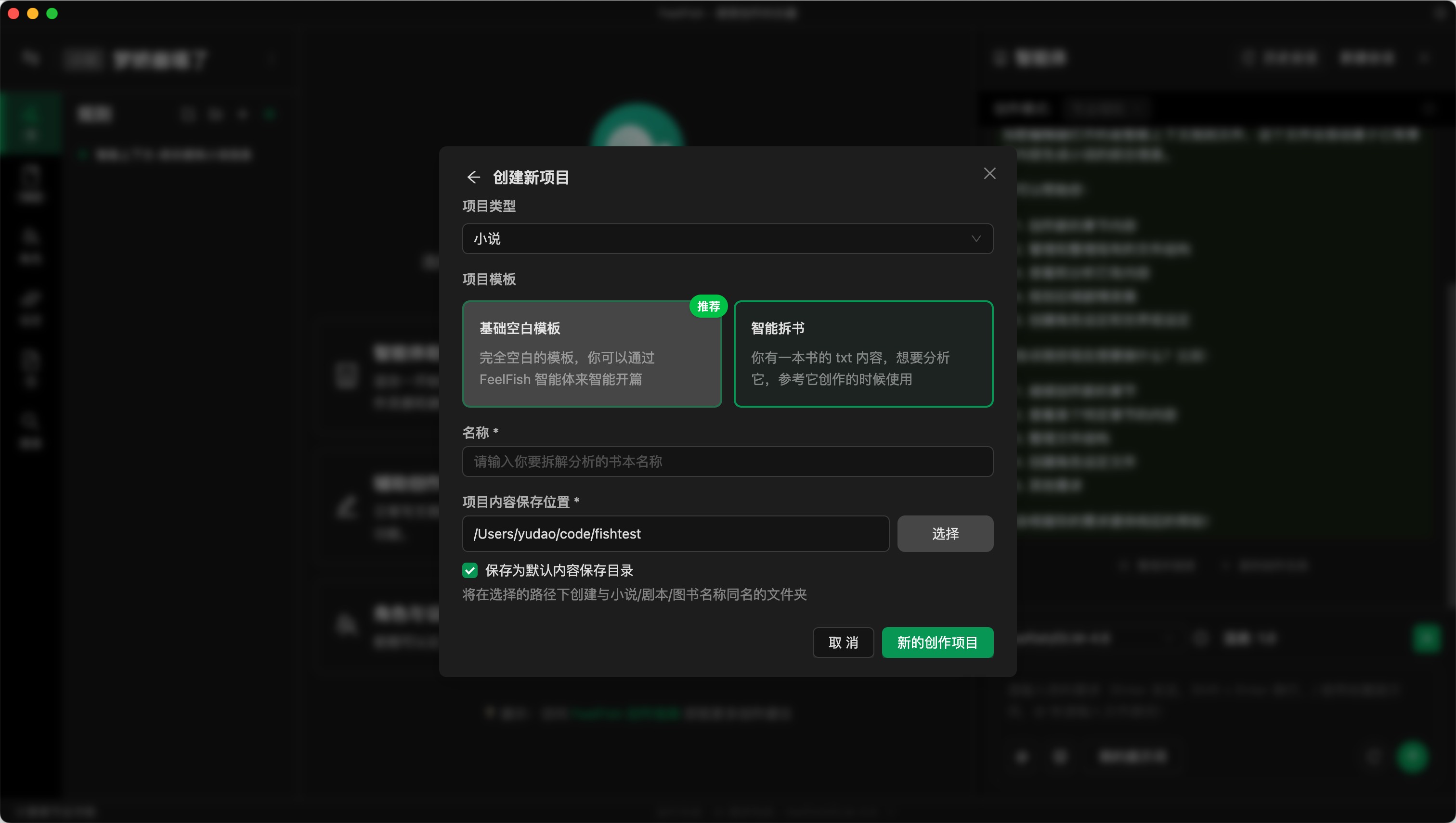
步驟一:基於智能拆書模板項目創建小說
點擊小說名稱左側的切換項目按鈕,然後點擊“新的創作項目”,選擇“智能拆書模板”,輸入你要拆的書的名稱,然後創建。
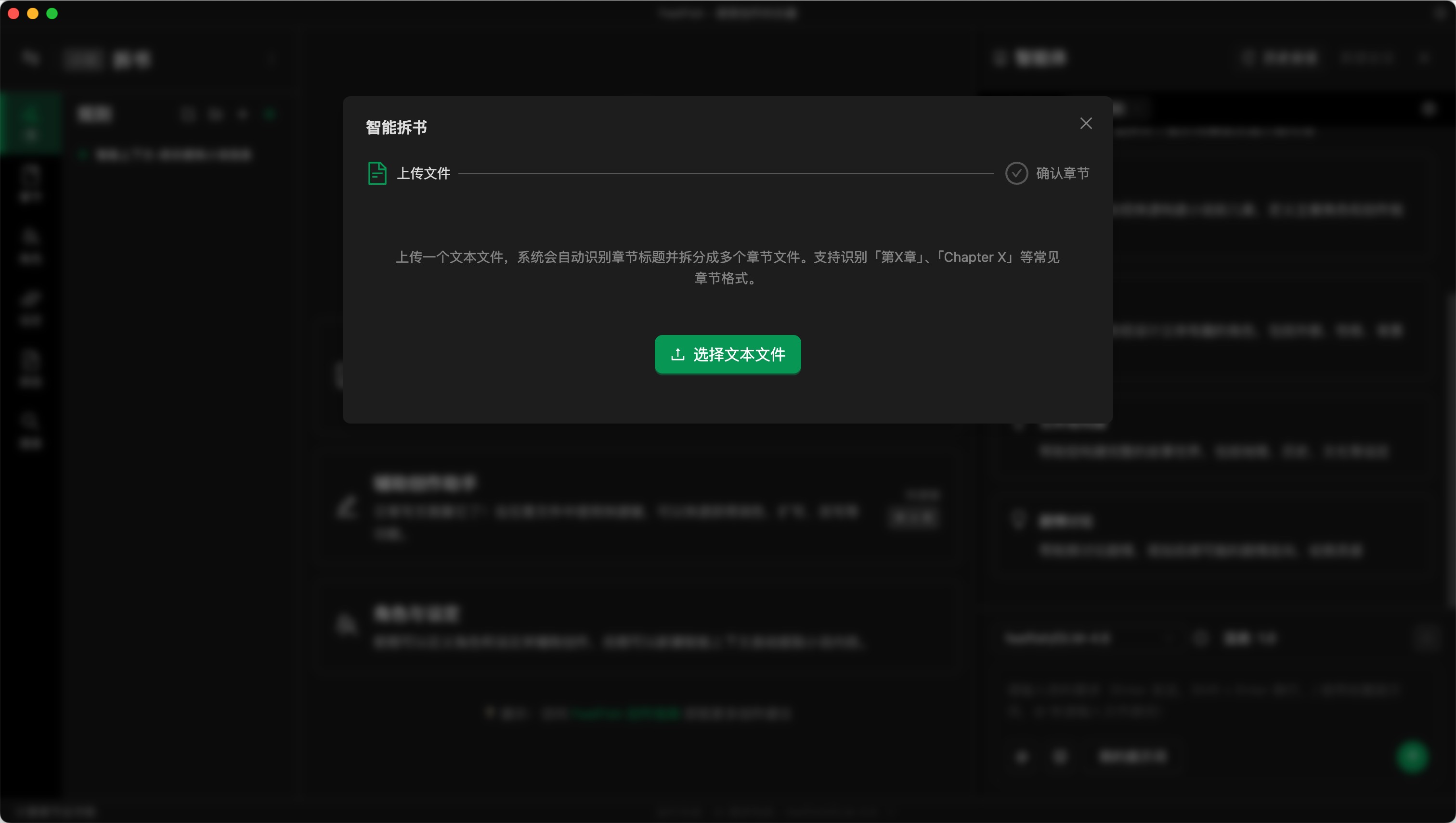
步驟二:導入完整的 TXT 文本
在彈出來的窗口中可以導入完整的 TXT 文本。或者當章節內容為空的時候,你也可以在章節內容列表那裡找到導入按鈕。
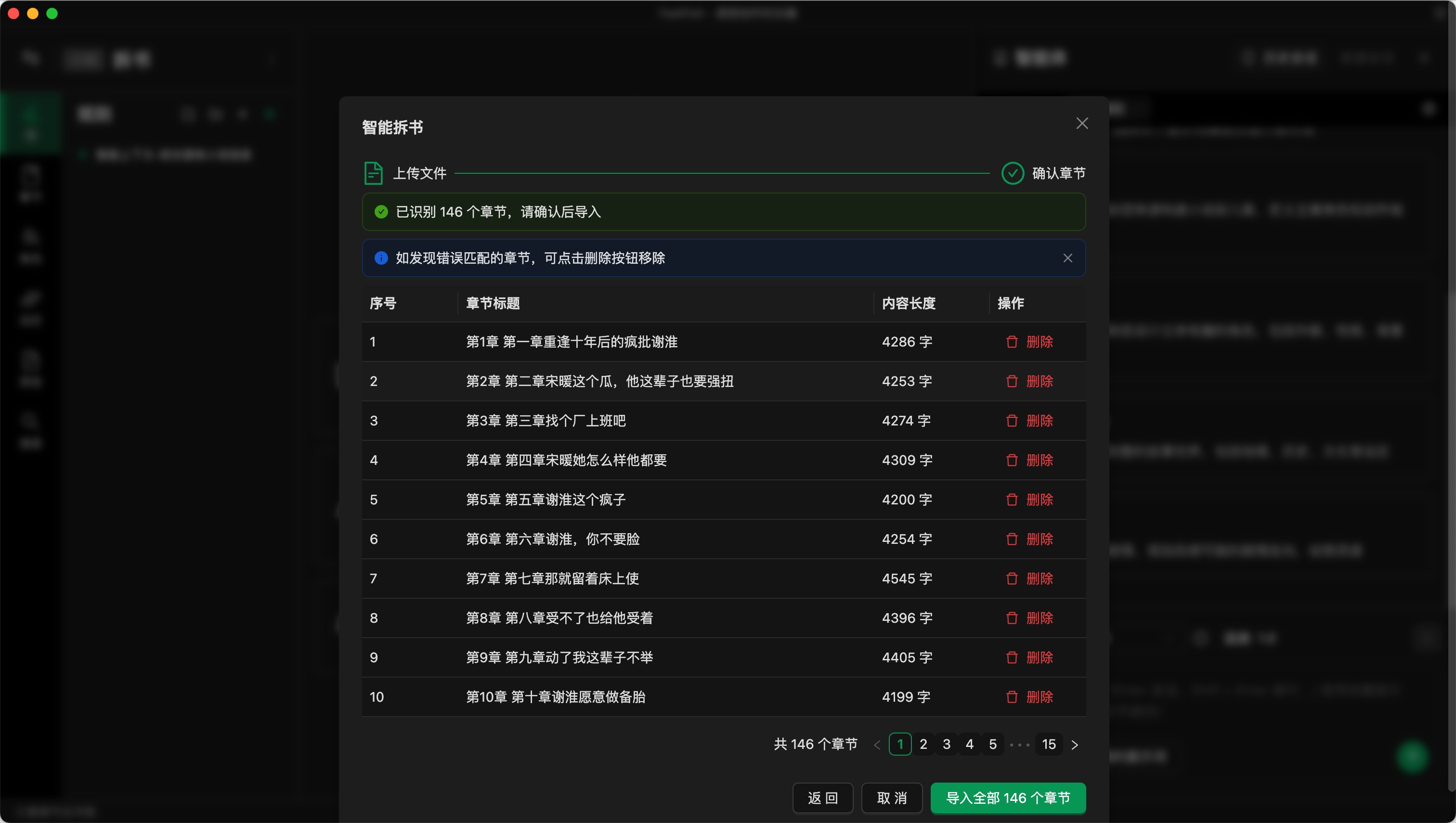
導入後會識別小說中的章節編號,把整個 TXT 拆解為獨立的章節。這個過程可能會匹配出錯,比如可能會把內容中單獨一行出現的數字也匹配為章節號。你需要手動檢查並刪除錯誤的匹配。
如果匹配有問題,請反饋給我們。我們會看看是否是你的文本格式我們沒有識別到。
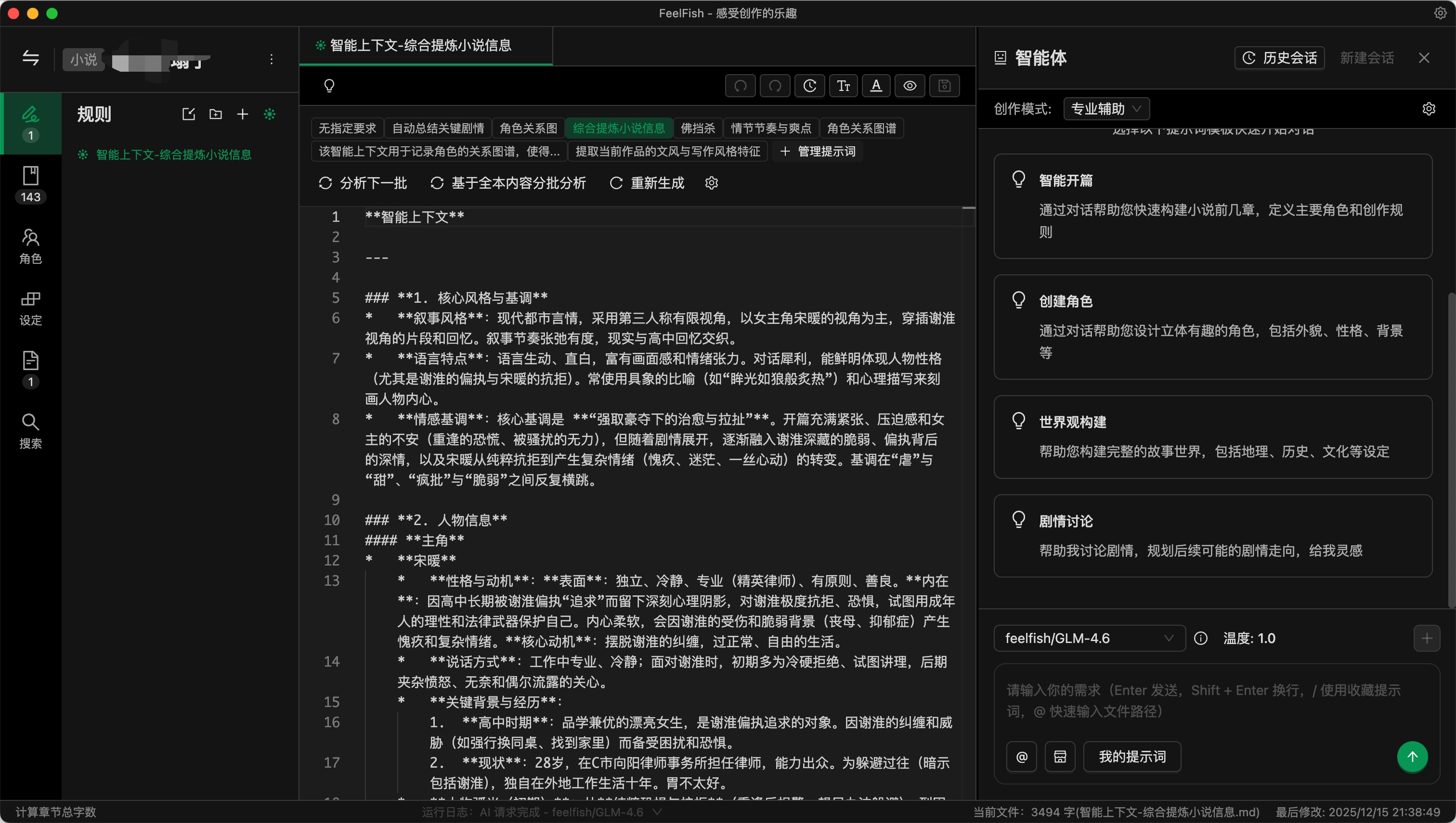
步驟三:基於智能上下文功能提取小說內容
智能拆書的原理其實就是基於 FeelFish 的智能上下文功能實現的。本質上就是基於小說章節分批識別,依靠 AI 提取小說內容。
智能上下文可以創建多個,你可以按照你的需求來提取不同的信息。每個智能上下文都可以有自己的提示詞,FeelFish 會基於對應智能上下文的提示詞來提取小說信息。
關於積分消耗
積分消耗和 FeelFish 的智能上下文功能一樣,都是基於 AI 請求的 Token 數來計算的。你可以選擇你要使用的模型來拆書,我們如果按照 DeepSeek V3.2 來算的話(每個輸入的 token 消耗 28 積分),大概兩個漢字對應一個 Token,一百萬字對應 50W Token,只看小說內容輸入的話需要 1400W 積分。加上最後的輸出和每次分批時輸入的上一次的智能上下文的結果,總消耗應該在 2000W 積分左右。
如果你新建多個智能上下文,一定時間內重複讀取的小說內容是有緩存的,只需要十分之一的積分。所以整體來看,創建個三四個個智能上下文,積分消耗應該在 5000W 以內(相當於高級會員的六分之一,實際情況請以實際消耗為準)。我們建議可以先分析幾個章節,看看效果如何。然後調整你的提示詞後再全量跑。
另外,你可以在智能體中基於已有章節內容讓 AI 幫你針對單個章節進行分析。
總之,FeelFish 的智能拆書功能非常的靈活和強大,你可以好好探索~